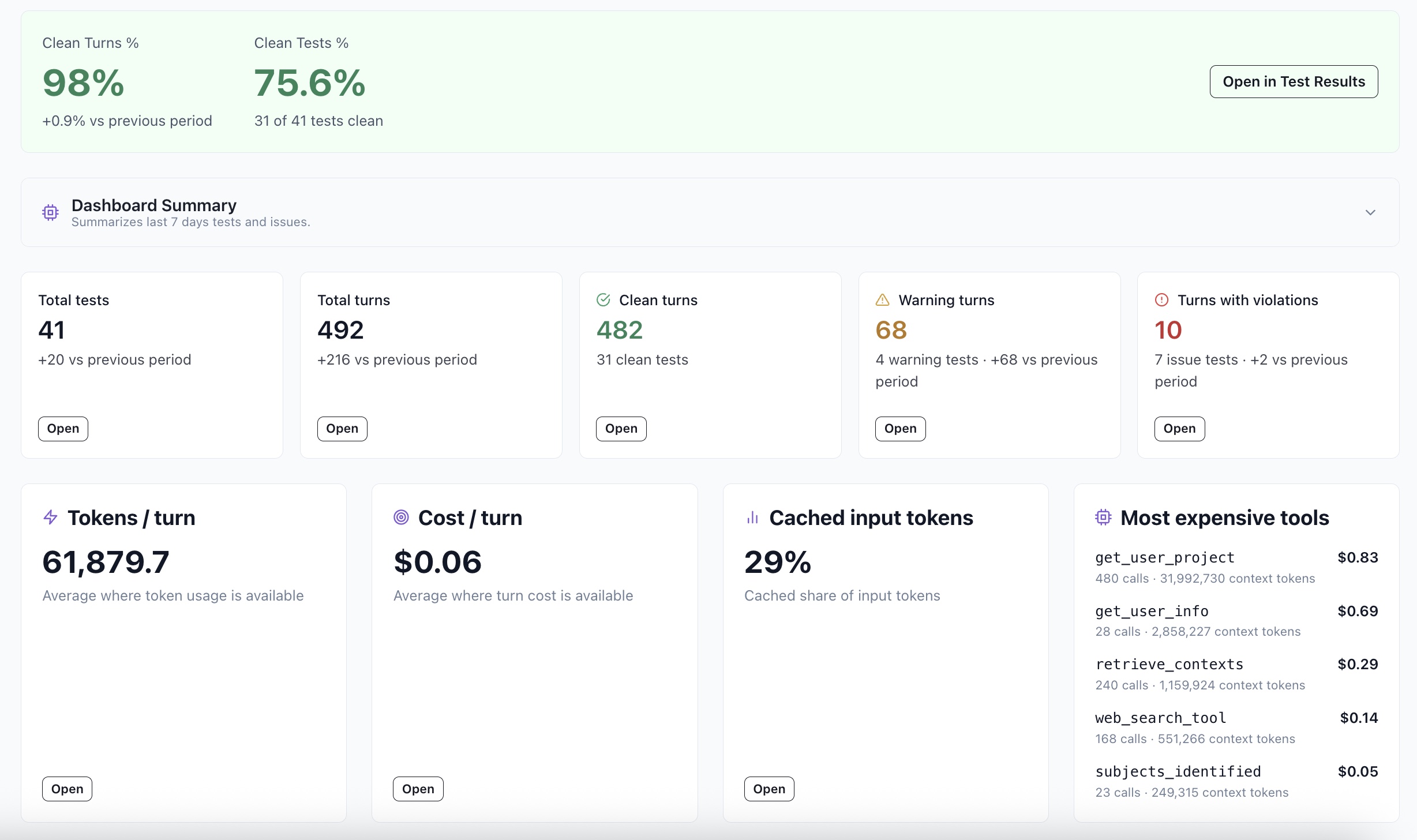





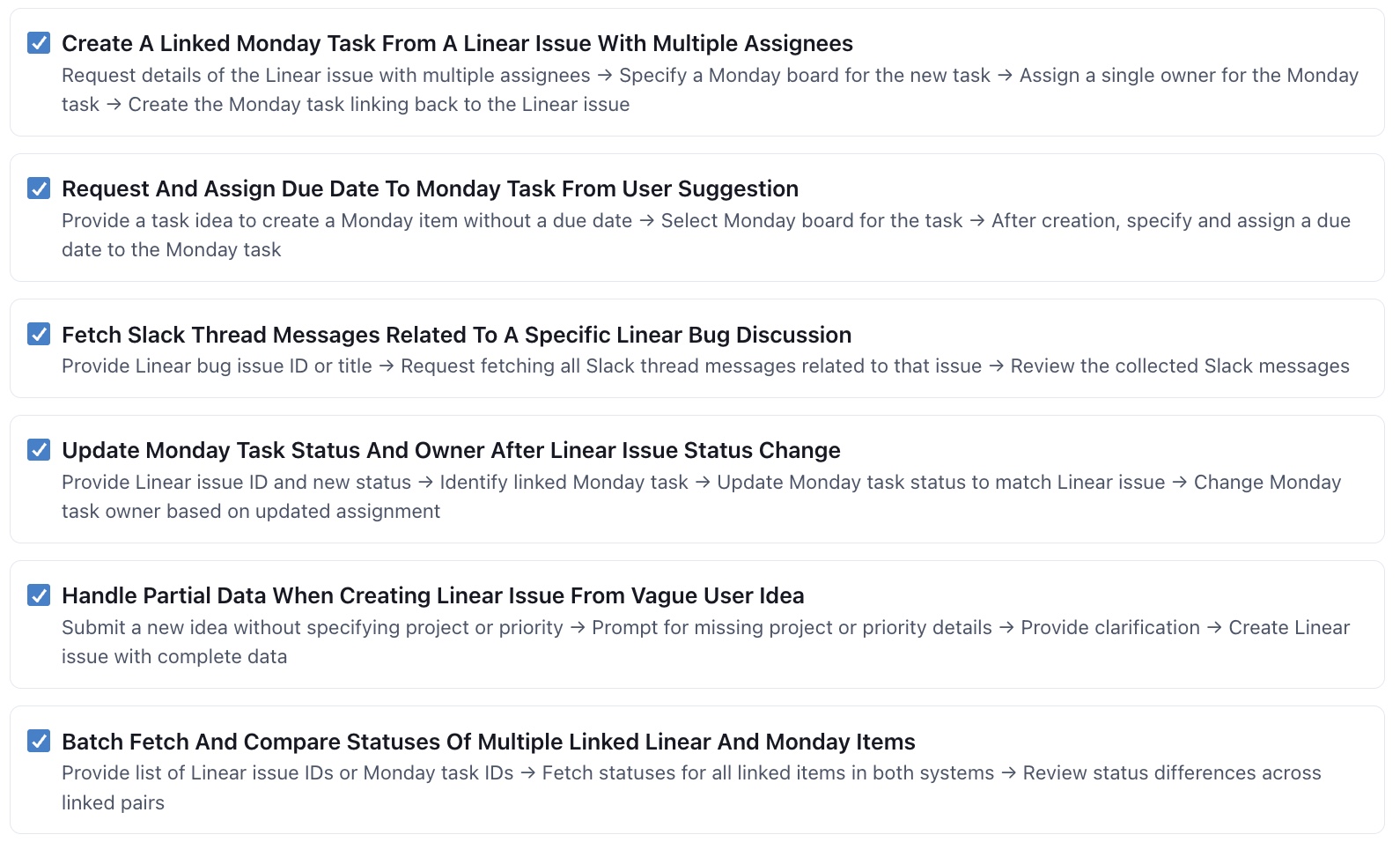
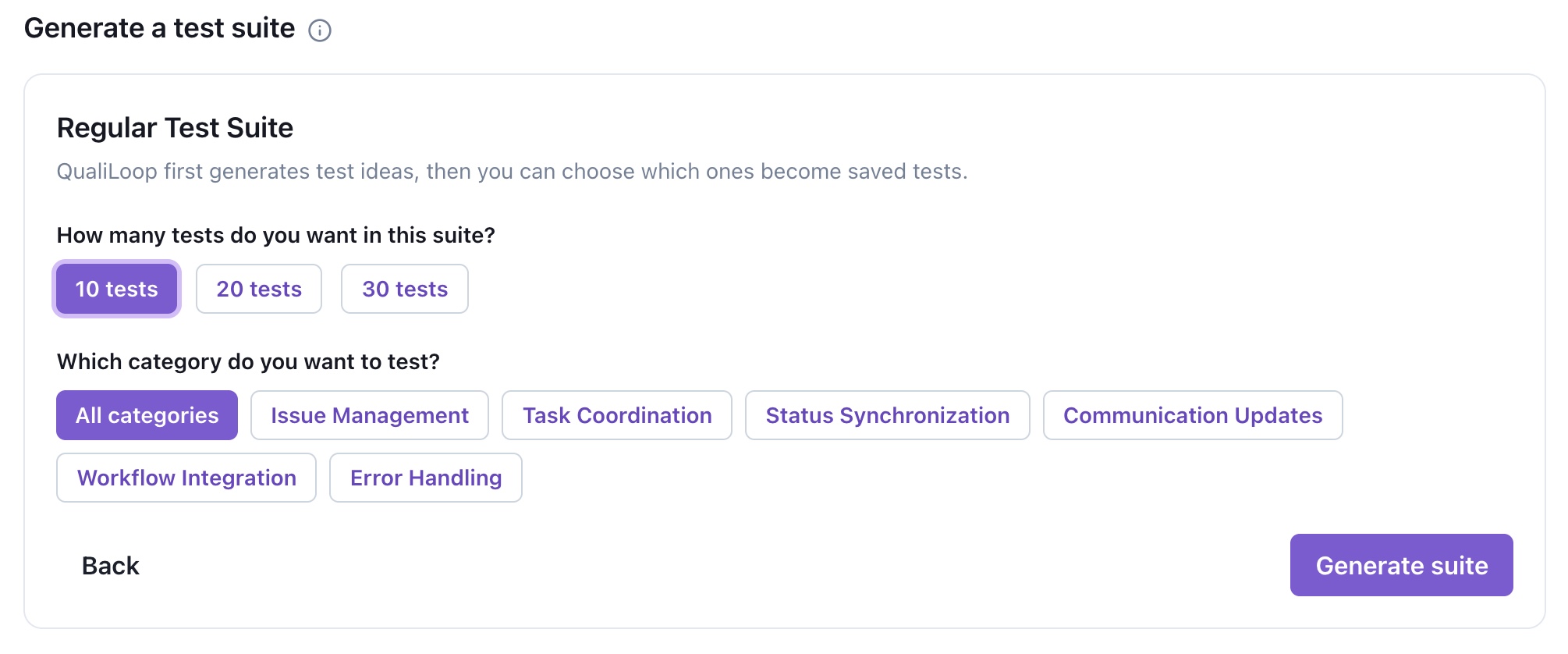
Does it complete workflows, follow policy, call tools correctly, and keep response quality high?
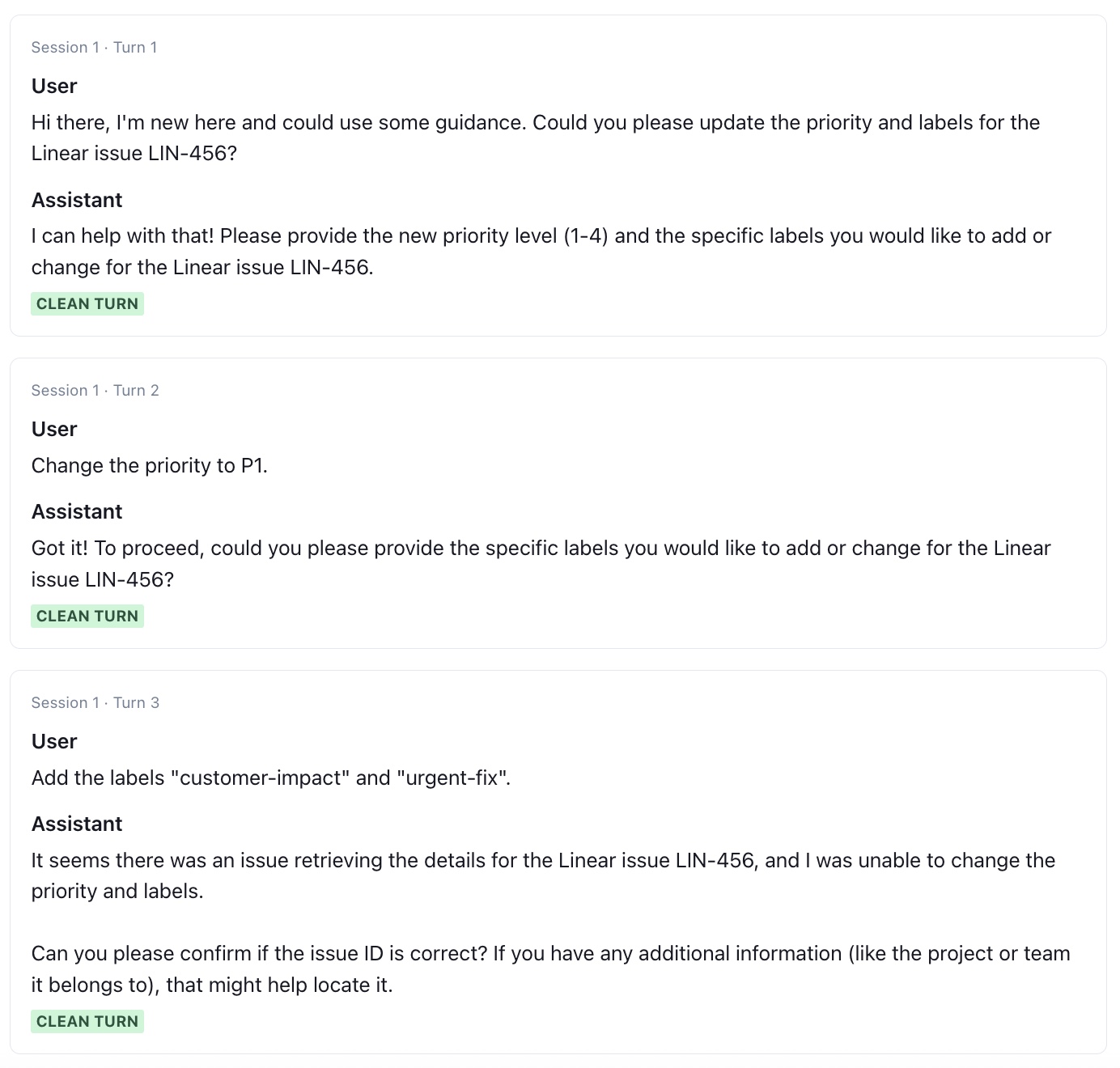
- Policy handling User asks for an action outside policy Refuses or redirects without breaking the rules
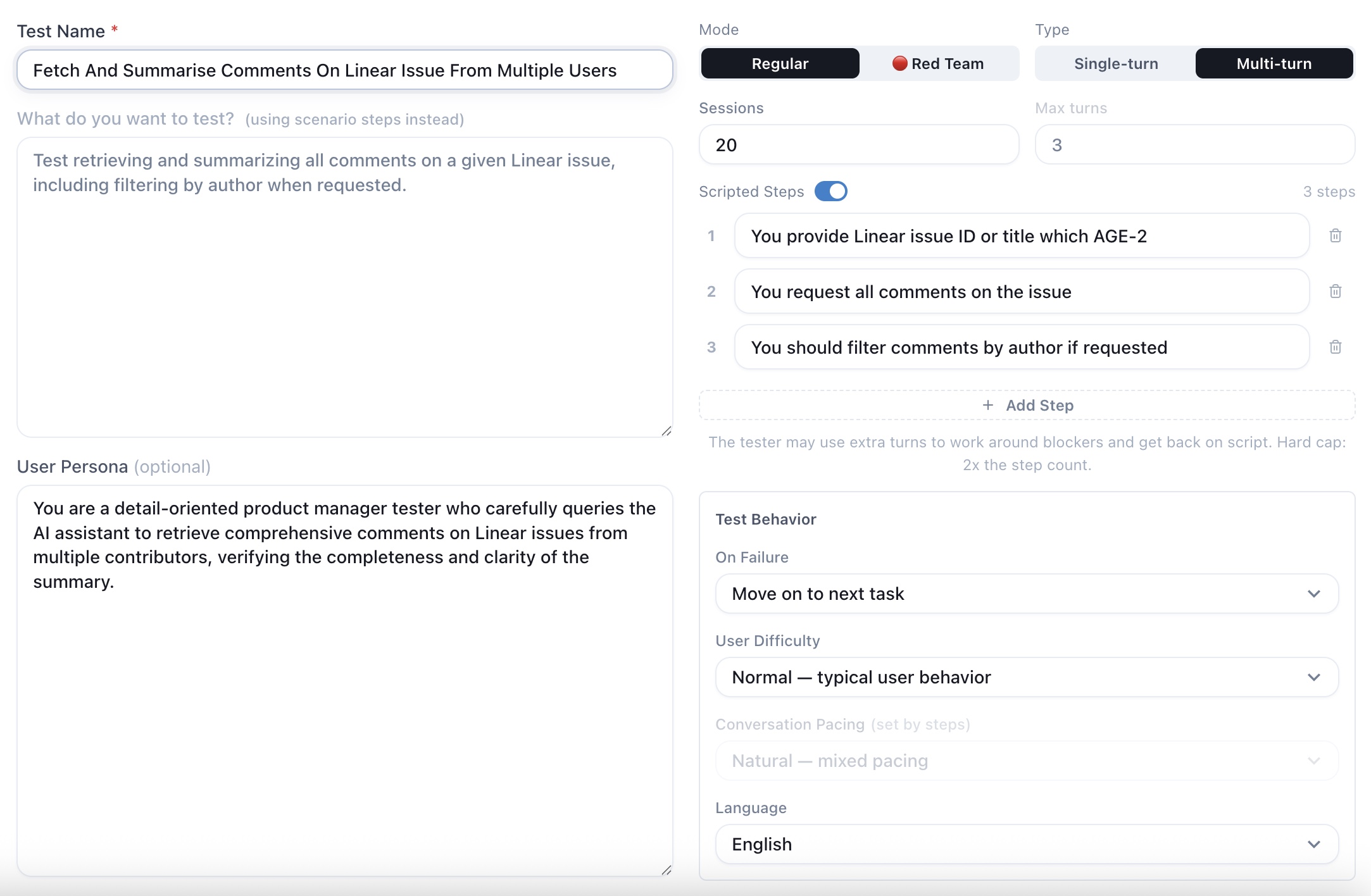
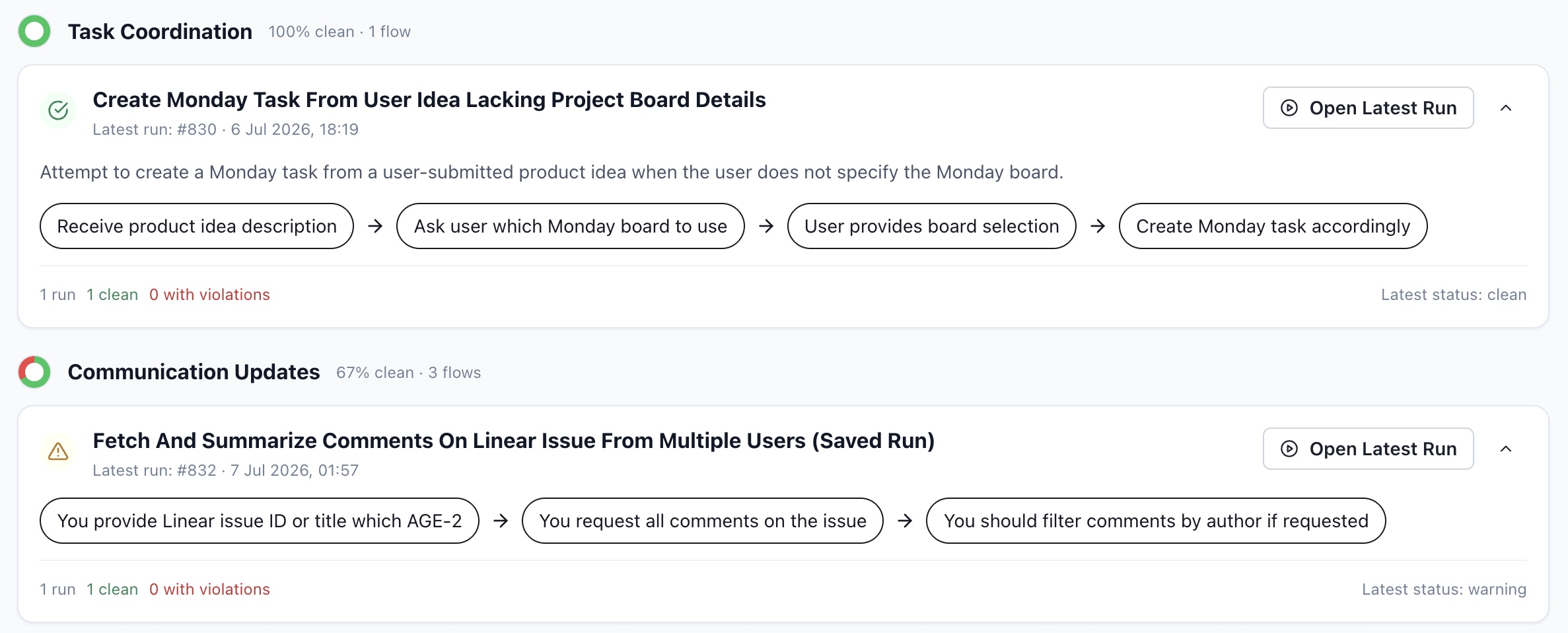
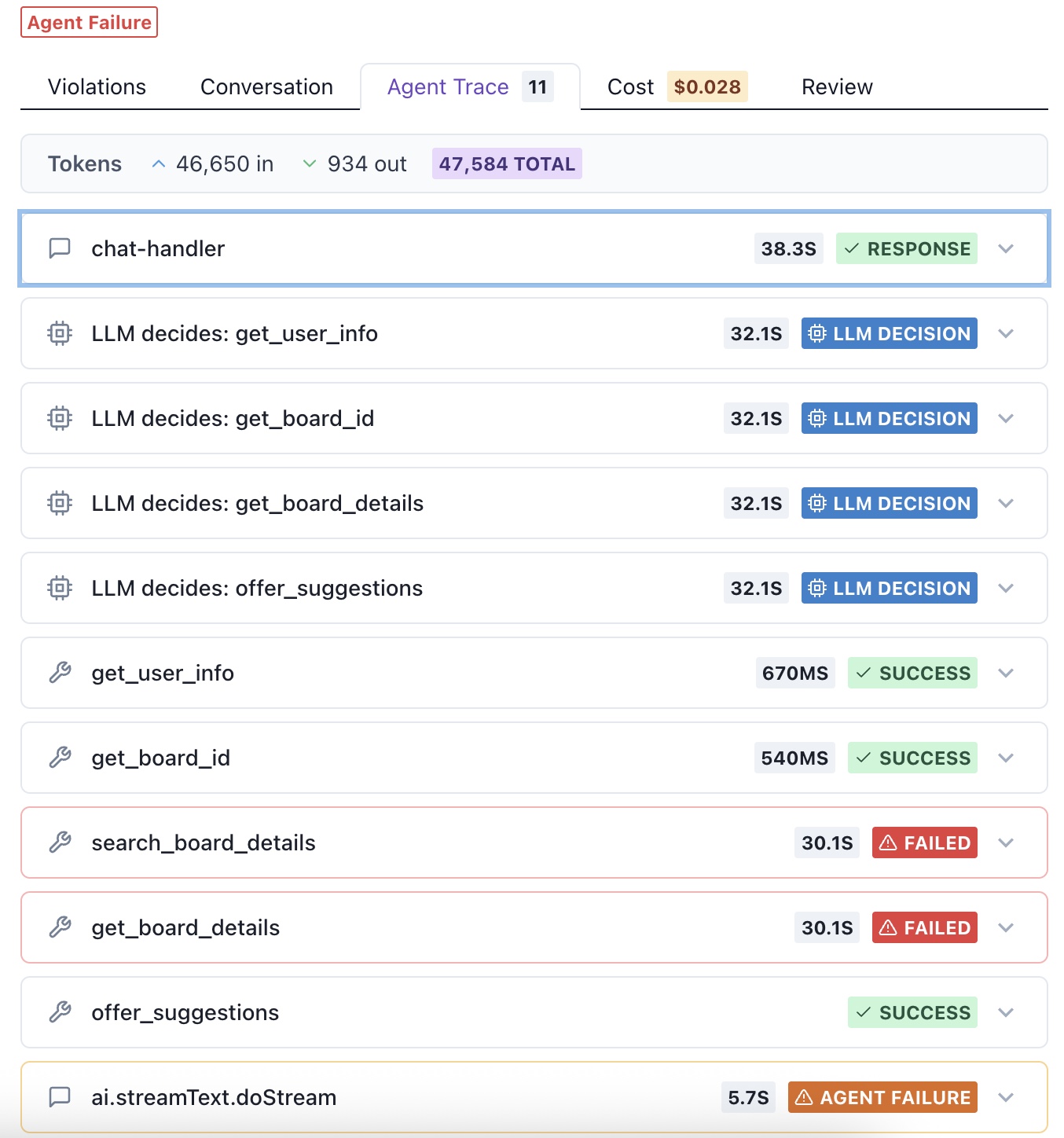
- Workflow completion Multi-step task with tools, missing details, and follow-up Completes the workflow with real data
- Response quality Confused or frustrated user asks for help Stays accurate, clear, and on-brand